
Where does a log-normal distribution “come from”?
The log-normal distribution shows up all over the place because it arises from a quite general process. That process is the multiplication of many positive random variables. The same way we associate the normal distribution with the addition of many random variables due to the central-limit theorem, we can also think of analogous behavior in the log domain. That is if we have some random variables 




Why is it like a power law?
The utility/prevalence of the log-normal distribution rises too because we can see that in some approximations, it maps to a`power-law’ distribution. First writing out the precise form, the log-normal distribution function in terms of the log mean 

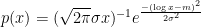
taking the log of both sides we have

or
![\log p(x)=-\log\left(\sqrt{2\pi}\sigma\right) +\frac{\mu^2}{2\sigma^2}-\log x\left[1+\frac{1}{2}\left(\frac{\log x}{\sigma}\right)^2+\frac{\mu}{\sigma^2}\right]](https://s0.wp.com/latex.php?latex=%5Clog+p%28x%29%3D-%5Clog%5Cleft%28%5Csqrt%7B2%5Cpi%7D%5Csigma%5Cright%29+%2B%5Cfrac%7B%5Cmu%5E2%7D%7B2%5Csigma%5E2%7D-%5Clog+x%5Cleft%5B1%2B%5Cfrac%7B1%7D%7B2%7D%5Cleft%28%5Cfrac%7B%5Clog+x%7D%7B%5Csigma%7D%5Cright%29%5E2%2B%5Cfrac%7B%5Cmu%7D%7B%5Csigma%5E2%7D%5Cright%5D+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
but if 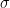


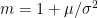

or
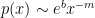
Thus the probability depends on a power-law of the independent variable.
The distribution is nice because it looks linear on a log-log scale. That is if we have some distribution 
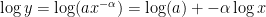

Notes/caution on power law distributions
I met an sociologist the other day who was studying the social networks involved in HIV epidemiology. I asked him a dumb physicist question, “what do the networks look like? are they power-law distributed?”. He smiled. “If you are used to looking for power-law distributions, then yes.”
His point was really well taken. In this example what I was asking about is the distribution of degree sizes (or number of edges coming out from nodes in a social network, or graph). That is, how many people have 3 contacts?, how many 5?, how many 50? It seems that many human networks (the internet is a good example) have multiple scales (5-50-500 etc), and that actually those distributions look linear on a log-log scale as described above. However, it has become fashionable to point to these relationships and draw out power laws. It turns out this fitting process is actually slippery, and Clauset, Shalizi, and Newman (arxiv) have a really nice albeit snarky paper on how to do this correctly, or not.
