So there are two main ways that we might typically take a dynamical system (expressed as a set of interacting differential equations) and make it into a stochastic simulation. They each have their strengths and weaknesses. I hope to describe these here concisely.
Let’s formalize the system a bit and call each state variable 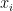 , and all rates
, and all rates 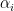 . The system is in general non-linear and can’t be expressed neatly, but for example we might have the Lotka-Volterra equations where prey is born at a constant rate, eaten with another rate, and predators die off exponentially when there is no prey with a final rate. Note these rates have different units here but that’s fine for now.
. The system is in general non-linear and can’t be expressed neatly, but for example we might have the Lotka-Volterra equations where prey is born at a constant rate, eaten with another rate, and predators die off exponentially when there is no prey with a final rate. Note these rates have different units here but that’s fine for now.
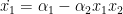

First, the reason to use a stochastic solver is often because of small numbers. For large simulations, it doesn’t matter if there are 100,000 prey and 5,500 predators, but what does matter is if we have a scenario with 100 prey and 5 predators. There cannot be 5.5 predators, and once there are zero predators, predators never return. So as a sanity check, it’s useful to see if these `burnouts’ or discrete numbered problems actually matter for your system before coding a stochastic implementation. Ok, on we go.
The first method is typically referred to as Gillespie’s direct method, though sometimes SSA for stochastic simulation algorithm. This method assumes that all reactions in the system are exponentially distributed based on their rate. Each process is independent and occurs at an average rate given by the deterministic dynamical system. The algorithm proceeds by looking at all possible transitions (in the above there are 3 possible “rates”:  . That is, either a prey is born, a prey is eaten, or a predator dies. The sum of all these rates
. That is, either a prey is born, a prey is eaten, or a predator dies. The sum of all these rates  determines the time until the next event. Computationally, we draw a uniform random number
determines the time until the next event. Computationally, we draw a uniform random number ![U\in[0,1]](https://s0.wp.com/latex.php?latex=U%5Cin%5B0%2C1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002) and solve
and solve  . If the sum
. If the sum  is large,
is large,  will be small. Each time a transition occurs, we choose which of the three available transitions based on their relative rates. Computationally this is achieved by normalizing the rates
will be small. Each time a transition occurs, we choose which of the three available transitions based on their relative rates. Computationally this is achieved by normalizing the rates  , drawing another uniform random number and determining where in the cumulative sum the random number falls. In Matlab for example, compute
, drawing another uniform random number and determining where in the cumulative sum the random number falls. In Matlab for example, compute
max(cumsum(r_i)/sum(r_i)>=rand())
The larger the rate, the more likely to happen, but the random number ensures some variability. This method is “direct”. It simulates all transitions. Unfortunately, it is extremely computationally expensive if one wants to simulate a time frame much longer than the typical event time.
An alternative is therefore the so called “tau-leap” method. It allows the user to specify the time-step (often denoted  , which I think is where the name came from) and then tabulate how many stochastic events occurred in this time step. This is essentially a stochastic Newton’s solver. For each transition, we draw the number of times that transitioned occurred in a time step from a distribution (often Poisson) given an average number of events
, which I think is where the name came from) and then tabulate how many stochastic events occurred in this time step. This is essentially a stochastic Newton’s solver. For each transition, we draw the number of times that transitioned occurred in a time step from a distribution (often Poisson) given an average number of events  in that time step. Thus, above we might have a random draw of
in that time step. Thus, above we might have a random draw of  prey births and
prey births and  predator deaths in some time-step. Note this still ensures discrete transitions and once predators die out, they cannot stochastically come back. Seems better? But, it has its own challenges because must be chosen artfully so that arguments of the probability don’t exceed 1, and if rates are very different in magnitude eventually the rounding sneaks up on you and a certain process never occurs.
predator deaths in some time-step. Note this still ensures discrete transitions and once predators die out, they cannot stochastically come back. Seems better? But, it has its own challenges because must be chosen artfully so that arguments of the probability don’t exceed 1, and if rates are very different in magnitude eventually the rounding sneaks up on you and a certain process never occurs.
A final alternative is a clever combination of deterministic and stochastic implementation. We call this a hybrid approach. It is well described by Alfonsi et al. 2005. We introduce the transition matrix that governs what happens in each transition as  . For example, our predator prey model matrix is
. For example, our predator prey model matrix is ![\mathcal{T}_{ij}=[[1, 0],[-1,1],[0,-1]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BT%7D_%7Bij%7D%3D%5B%5B1%2C+0%5D%2C%5B-1%2C1%5D%2C%5B0%2C-1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002) .
.
We separate the transitions into deterministic 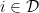 or stochastic
or stochastic  . The algorithm proceeds by drawing exponentially distributed random variables
. The algorithm proceeds by drawing exponentially distributed random variables 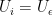 for
for 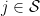 . Then, the evolution of proceeds deterministically as
. Then, the evolution of proceeds deterministically as

which could be solved with the Newton solver for example. Meanwhile, the stochastic transitions accrue probability with the evolution equation

until a certain time when 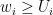 . Then that specific stochastic transition
. Then that specific stochastic transition  occurs, making
occurs, making  , and the next random variable resets the probability of that transition, i.e.
, and the next random variable resets the probability of that transition, i.e. 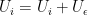 . This method is useful for separation of scales, and seems that the largest challenges are in implementation (might need to use higher order solvers than Newton for the deterministic solving) and in choosing which variables to allow to be deterministic a priori.
. This method is useful for separation of scales, and seems that the largest challenges are in implementation (might need to use higher order solvers than Newton for the deterministic solving) and in choosing which variables to allow to be deterministic a priori.

