

In physics, and elsewhere, stochastic processes are often simulated as white-noise processes. These processes are idealized and typically justified as the limit of exponentially correlated colored noise. The white approximation is not always accurate, and sometimes it is necessary to simulated colored noise.
Following Fox’s work [1], I wrote this note to demonstrate how to simulate colored noise.
Consider the stochastic differential equation where the time derivative of state variable 




We can write a stochastic differential equation (SDE) then

where the mean of the noise is zero, and autocorrelation (correlation with itself over time) is given by the Dirac delta function
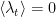

with 
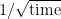



a constant for all frequencies. The process only requires the first two probability moments because it is Gaussian. We now have the stochastic difference equation

and we see that because the noise is additive (and noticing 
To discretize the solution and compute numerically, we calculate an increment of the Wiener process (i.e. 

![R_1,R_2 \in [0,1]](https://s0.wp.com/latex.php?latex=R_1%2CR_2+%5Cin+%5B0%2C1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
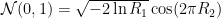
The Euler-Marayuma scheme then leads to the numerical implementation

If instead colored noise is desired, the easiest to implement is exponentially correlated noise 


where 
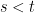

so that the power spectrum is for exponentially distributed noise is Lorentzian

We generate the trajectories of a variable

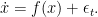
A subtle note is that the initial value of the exponential noise can be chosen as a Gaussian random variable so that really we have that the mean of the auto-correlation function is exponentially distributed for all initial values of 

(1) call
(2) compute
(3) generate another Gaussian random number
(4) compute 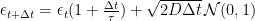
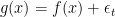
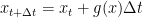
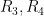
[1] Fox et al. “Fast, accurate algorithm for numerical simulation of exponentially correlated colored noise.'' Physical Review A 38.11 (1988): 5938.
[2] Box and Muller. “A note on the generation of random normal deviates.'' The Annals of Mathematical Statistics 29 (1958): 610-611.
