

I often return to Jaynes’s wonderful 1957 paper “Information theory and statistical mechanics”. Starting from the entropy as defined by Shannon, Jaynes explains lucidly how to decipher the correct probability distribution to describe a statistical phenomenon. The correct distribution derives from the pieces of information that we might have about the phenomenon. Using the pieces and obeying the “principle of maximum ignorance”, the proper distribution can be computed.
The form of the definition of Shannon entropy is interesting in itself. Shannon defined the entropy as the expected value of the information contained in a message. The information of a message 


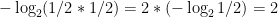

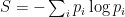
The two coin flipping situation has (if the coins are fair) an equal probability for heads and tails and thus 
Let 
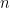


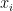

Can we now infer the mean of some other function 
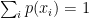


Laplace answered the questions with his ‘principle of insufficient reason’: that no assumptions should be made about the probabilities. Using his principle, for example, if no information is given about the probability distribution
When we know the mean and the definition of a probability distribution, we can use Lagrange multipliers to enforce two constraints:

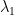
Using 
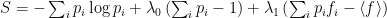
where then to be maximal we must have 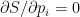
![\frac{\partial S}{\partial p}= -\sum_i \left[ \log p_i - 1 + \lambda_0 + \lambda_1f_i \right] = 0](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+S%7D%7B%5Cpartial+p%7D%3D+-%5Csum_i+%5Cleft%5B+%5Clog+p_i+-+1+%2B+%5Clambda_0+%2B+%5Clambda_1f_i+%5Cright%5D+%3D+0+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
where the chosen function 




so that the maximally entropic distribution is an exponential function. This should seem familiar to those who have seen the Maxwell-Boltzmann distribution for the micro-canonical ensemble in statistical physics. The normalization can be recovered.
What if we add another constraint? For example, if we constrain the standard deviation, thereby constraining the second moment, we end up with the omnipresent Gaussian distribution. It is really cool that the “max-ent” method for inferring distributions agrees with common assumptions made with intuition but less mathematical rigor. The note is meant to illustrate this powerful technique as well as showing how we can actually define maximum ignorance in making inferences.
